
Same Building Blocks, Different Machines: Why E2E Driving and E2E Robotics Are Making Four Different Bets
Both fields are building learned sensing-to-actuation pipelines with the same components. Four architectural strategies are emerging - and each domain populates the map differently.


Figure AI’s Helix runs a vision-language model at 7-9 Hz for scene reasoning and a visuomotor policy at 200 Hz for motor control. In a different lab, a team at Tsinghua’s MARS Lab built DriveVLM with the same split: a VLM for low-frequency trajectory prediction refined by a faster planner. Two teams, two domains, zero coordination and they arrived at the same architectural partition.
This isn’t convergence in the way most people mean it. It’s the same physics constraint forcing the same structural answer: VLM inference latency and real-time control frequency are incompatible by one to two orders of magnitude. Any system that needs both semantic reasoning and high-frequency actuation will eventually decouple them.
But the dual-system VLA is just one of four distinct strategies for learned sensing-to-actuation that are emerging across autonomous driving and robotics. Both fields are pursuing the same high-level objective: replace hand-engineered pipelines with learned systems that map sensor inputs to actions. They’re using the same building blocks: transformers, diffusion models, VLM backbones, flow-matching action decoders. And yet the system architectures are diverging.
Most commentary treats “end-to-end” as one thing. It’s at least four. Here’s the map and the punchline is that your data asset, not your architecture preferences, determines which strategy you can actually execute.

Why E2E, and Why Now
The shift toward learned sensing-to-actuation comes from a structural limitation of hand-engineered pipelines. Traditional stacks decompose the problem into modules perception, prediction, planning each typically optimized against its own loss function. The result is information bottlenecks at every module boundary. A perception module trained to minimize detection error doesn’t propagate what the planner needs. A prediction module trained on trajectory forecasting doesn’t know what the planner can actually execute. Errors compound across stages, and the system can’t jointly optimize for the thing that actually matters: the final action.
E2E learning removes those bottlenecks by letting gradients flow from the planning objective back through the full stack. In principle, every component learns to produce representations that serve the downstream task, not just its own local metric. Both driving and robotics hit this same wall independently. AV teams found that hand-tuned perception-to-planning interfaces couldn’t scale past a certain complexity of driving scenarios. Robotics teams found that scripted pick-and-place pipelines couldn’t generalize across object geometries. The prescription was the same: let the learning signal flow end-to-end and let the network figure out what intermediate representations it actually needs.
What makes the current moment different is that the building blocks finally exist to do this at production scale. Transformers provide flexible sequence modeling across modalities. Diffusion and flow-matching give continuous, multimodal action generation. MultiModal LLM/ VLM backbones offer internet-scale semantic grounding. Three years ago, these components were research artifacts. Today they’re shipping in vehicles and on robot hardware.
Shared Lineage, Diverging Bets
The shared lineage runs deep. Both domains independently converged on the same solutions to the same problems: BEV or ViT-based spatial encoding to go from pixels to plannable representations (UniAD in driving, RT-2/OpenVLA in robotics). Multi-step action prediction to manage compounding error (VAD trajectory waypoints, ACT action chunks, Diffusion Policy denoised trajectories). Migration from discrete to continuous action representations through diffusion and flow-matching (π0 at 50 Hz, GR00T N1 at 120 Hz).
In my experience building Rivian’s Generation 2 Autonomy+ perception stack, the modular architecture was already a substantially complex venture. Going directly to E2E would have meant risking major program delays and shaking investor confidence, a trade-off most teams won’t make until the modular approach visibly hits its ceiling.
The building blocks are converging. The system architectures are not. Four strategies explain why.
Four Strategies for Sensing-to-Actuation
Strategy 1: Modular End-to-End
Retain explicit task modules - perception, prediction, planning - but train them jointly so gradients flow end-to-end.
In driving: UniAD cascades through BEV encoding, tracking queries, motion prediction, occupancy forecasting, and planning, all differentiable. VAD replaces dense BEV with vectorized map representations. PARA-Drive‘s ablation study is the one worth reading closely: removing most inter-module connections actually improved planning robustness, and a fully parallel architecture matched the cascaded approach at 2.77x the inference speed.
In robotics: No strong analog. Robotics never built the deep modular E2E tradition that AV developed over 2022-2024. Most robotics systems that use explicit modules still train them separately.
Strategy 2: Monolithic End-to-End (No VLM)
Collapse the pipeline entirely into a single learned model with no vision-language backbone.
In driving: Tesla’s FSD v12 processes eight cameras through a unified neural network and outputs steering, acceleration, and braking directly. Trained on over ten million video clips from a fleet of millions of vehicles.
In robotics: Diffusion Policy (Chi et al., RSS 2023) represents the visuomotor policy as a conditional denoising diffusion process - image observations in, action trajectories out. No language, no VLM. Averaged a 46.9% improvement across 12 benchmark tasks. ACT (ALOHA) uses a CVAE transformer to predict action chunks from visual input, again with no language component. These are the workhorses of current manipulation research.
Strategy 3: Single-System VLA
Build on a pre-trained vision-language model and fine-tune it to output actions in a single forward pass. The VLM backbone provides internet-scale semantic grounding. “VLA” - vision-language-action - is the name for this architectural pattern.
In driving: Waymo’s EMMA, built on Gemini, represents all driving outputs as natural language text tokens. Co-training across planning, object detection, and road graph estimation improves all three tasks. Li Auto explicitly adopted a VLA architecture in production, integrating E2E and VLM into a unified system.
In robotics: RT-2 (Google DeepMind) fine-tunes PaLI-X on robot trajectories and outputs actions as discrete text tokens. OpenVLA (Stanford) uses a Llama-2 backbone with DINOv2/SigLIP dual encoders, trained on 970K episodes across 22 embodiments. At 7B parameters, it outperforms the 55B-parameter RT-2-X by 16.5% in task success rate. π0 (Physical Intelligence) extends this with a flow-matching action expert generating continuous 50 Hz actions.
Strategy 4: Dual-System VLA
Decouple the VLM (slow reasoning, scene understanding) from the action policy (fast, continuous motor control). Both systems are trained end-to-end to communicate, but they operate at different frequencies.
In driving: DriveVLM uses a VLM for low-frequency trajectory prediction refined by a conventional planner. Senna uses a VLM to generate meta-actions (speed and path decisions) that feed into an E2E trajectory model.
In robotics: Figure AI’s Helix pairs a VLM (System 2, 7-9 Hz) with a visuomotor policy (System 1, 200 Hz) for full humanoid upper-body control - arms, hands, torso, head, fingers. NVIDIA’s GR00T N1 follows the same split: Eagle-2 VLM backbone (1.34B parameters) feeds a DiT-based flow-matching policy at 120 Hz, totaling 2.2B parameters. Trained on a data pyramid spanning internet video, synthetic data from Omniverse, and real teleoperation.
Where the Domains Diverge
The taxonomy matters because the constraints driving architectural choices are structurally different between driving and robotics, even when the strategies overlap.
The tokenization wall. Driving involves two to three continuous values at roughly 10 Hz. RT-2‘s approach of discretizing actions into 256 bins per dimension handles this comfortably. A humanoid upper body - Helix controls arms, hands, torso, head, fingers across 35 degrees of freedom. Discretizing at 256 bins per dimension yields approximately 10^84 possible actions per timestep. A physical impossibility, not a scaling challenge. That forced π0, Helix, and GR00T N1 toward continuous action generation through flow-matching. Embodiment degrees of freedom dictate the action representation. Strategy 3 (single-system VLA with discrete tokens) works for driving but hits a wall for high-DoF robotics.
Compute and latency budgets and the thermal ceiling. EMMA runs Gemini-scale inference at hundreds of milliseconds per frame. Tesla’s HW4 runs individual perception networks at under 25 ms. GR00T N1‘s DiT policy runs at 120 Hz (~8 ms) while its VLM operates at ~10 Hz (~100 ms). Helix‘s System 1 runs at 200 Hz (~5 ms).
The latency gap is the first-order constraint. The second-order constraint is thermal and power management under sustained inference and this applies differently across compute classes. Mobile devices are the extreme case: the iPhone 16 Pro loses 44% of ML inference throughput within two sustained cycles under passive cooling. Automotive and robotics SoCs have active cooling, but the constraint doesn’t disappear it shifts from thermal throttling to power budget allocation across concurrent workloads. When you’re running perception, prediction, and planning simultaneously on the same chip, the thermal ceiling determines what you can sustain, not what you can burst.
I’ve lived this constraint across compute classes. On NVIDIA AGX Drive Orin, my team meticulously budgeted compute and data movement costs to avoid compromising EPA range targets and safety-critical customer experience, every watt matters when it comes out of the battery. On Apple Vision Pro, I characterized and constrained over a dozen concurrent CV algorithms to a sub-watt power envelope, subject to skin temperature limits, safety requirements, and neuroscience constraints. The physics is the same whether your chip is in a headset, a car, or a humanoid.
Data pipeline economics. Tesla’s fleet generates continuous driving video at massive homogeneous scale (Strategy 2). Open X-Embodiment provides over 2.4 million episodes across 22 robot types (Strategy 3). GR00T N1‘s data pyramid spans internet video, synthetic data, and real teleoperation (Strategy 4). Your data asset determines your quadrant.
Contact dynamics. Driving is largely contact-free - trajectory generation in free space. Manipulation is contact-rich - forces, torques, and compliance matter at every timestep. This is why Diffusion Policy‘s ability to handle multimodal action distributions (multiple valid grasps for the same object) was the breakthrough for manipulation, while driving planners can often get away with unimodal trajectory regression. Strategy 2 (monolithic E2E) expresses differently across the two domains for this reason.
Safety as an architectural driver. Each strategy handles graceful degradation, OOD detection, and runtime monitoring differently. Strategy 1 can shed modules and fall back to reduced functionality. Strategy 2 is a single point of failure. Strategy 4 can continue with System 1 alone if System 2 fails. The comparison table above captures the high-level split, but the full safety analysis - including how ISO/PAS 8800, SAFE (NeurIPS 2025), and conformal prediction change the picture, deserves its own treatment. That’s the next on the signal path substack.
The production lens. Architecture papers optimize for task accuracy. Production teams optimize for five things that rarely appear in those papers: interpretability, reproducibility, maintainability, deployment cost, and continuous improvement. Each strategy handles them differently.
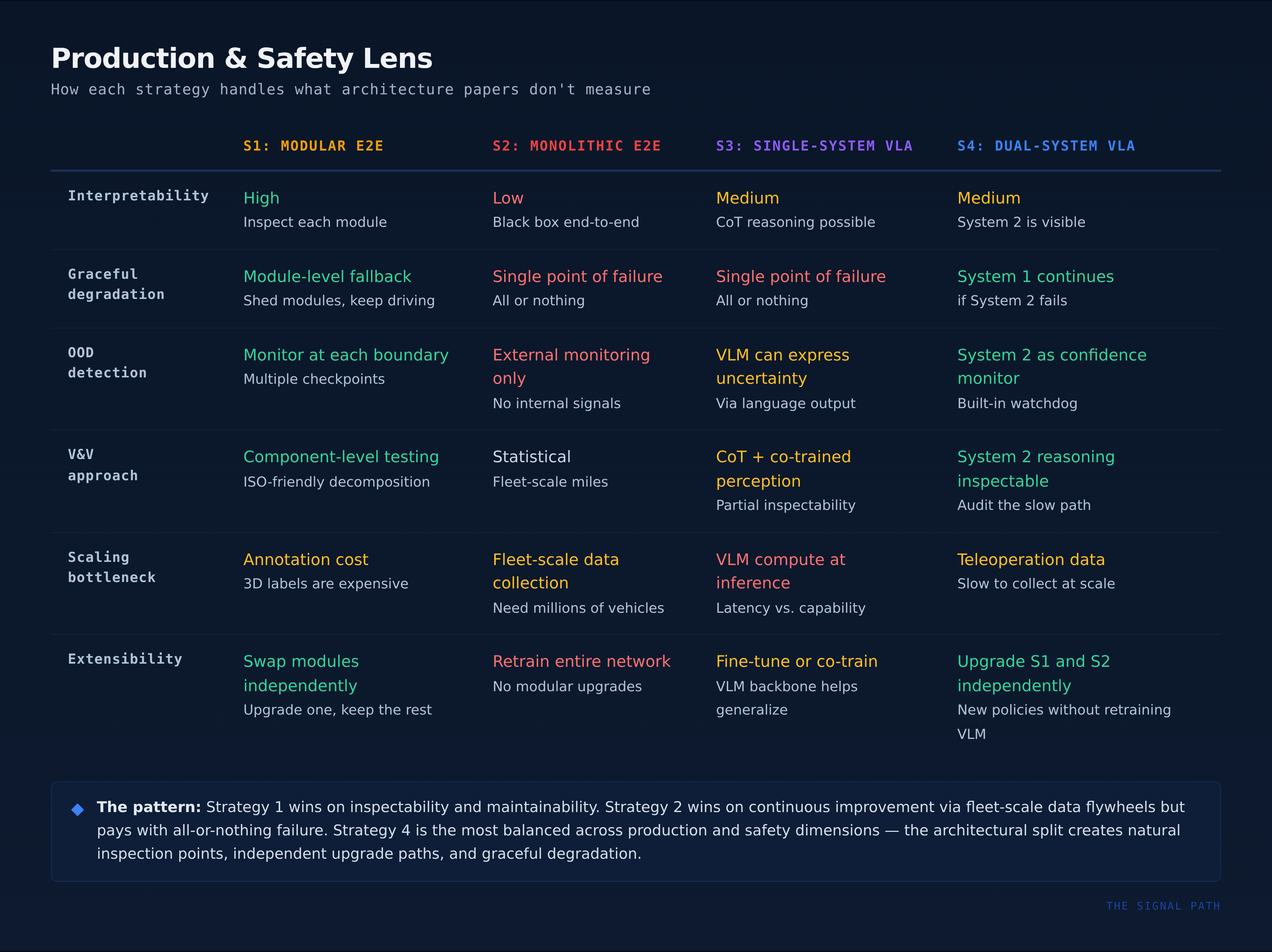
The pattern across both scorecards: Strategy 1 (modular E2E) wins on inspectability and maintainability. Strategy 2 (monolithic) wins on continuous improvement through fleet-scale data flywheels but pays for it with all-or-nothing retraining and a single point of failure. Strategy 4 (dual-system VLA) is the most balanced across production and safety dimensions because the architectural split between reasoning and control creates natural inspection points, independent upgrade paths, and graceful degradation.
In my experience, reproducibility was the dimension that determined whether an architecture survived past v1. If you can’t reliably reproduce a failure, you can’t validate the fix — and a team that can’t validate fixes stops shipping.
The benchmark trap. There’s a result from the open-loop evaluation literature that matters for anyone comparing strategies based on leaderboard rankings. Li et al. demonstrated that completely removing all camera input from VAD - blanking the visual stream - barely degraded planning performance on nuScenes, as long as ego velocity and position history were available. The model had learned to predict plausible trajectories from ego status alone, without meaningfully using perception.
The problem goes beyond VAD. Most nuScenes scenes involve driving straight at roughly constant speed. A model that predicts “keep doing what you were doing” scores well from ego status alone. NeuroNCAP (ECCV 2024) confirmed the consequence: E2E planners that excel in open-loop show critical failures in closed-loop safety scenarios, where the system’s decisions change the world it then has to perceive.
My team hit this exact problem deploying our v0 unified BEV model. It performed well on internal benchmarks but turned out to be overfitting to radar signals high scores on paper, brittle in the field.
This changes the evaluation of Strategy 2 and Strategy 3. Impressive benchmark numbers may reflect ego-status overfitting rather than genuine perceptual capability. Strategy 1 is partially protected because intermediate outputs can be independently validated. For robotics, the analog question: how much of reported VLA task success comes from the VLM’s scene understanding versus positional priors in the proprioceptive state?
The Missing Experiment
The convergence counterargument is simple: everything is heading toward one architecture. Li Auto shipped a VLA in production. SmolVLA (450M parameters, Hugging Face) matches models ten times its size. The building blocks - ViT encoders, diffusion action heads, transformer sequence models - are shared across all four strategies.
That case has merit at the component level. EMMA‘s co-training result is a good example: adding perception and road graph tasks improved planning performance. That’s a strong result on nuScenes. The question worth testing is whether that co-training benefit persists at fleet scale, where the joint optimization surface is vastly more complex and task interference becomes harder to manage. If it does, that’s evidence for Strategy 3 scaling. If it doesn’t, the joint training approach may need to give way to the decoupled optimization of Strategy 4.
Where the convergence argument breaks is at the system level. PARA-Drive demonstrated this for driving: systematically ablating a modular E2E stack showed that most inter-module connections were redundant. A parallel architecture achieved leading results at 2.77x speed. That was a precise empirical answer to the question of what structure a learned driving system actually needs.
The equivalent experiment for VLAs hasn’t been run. Here’s the specific protocol I’d want to see. Take GR00T N1 (2.2B parameters, 1.34B in the Eagle-2 VLM) and run three conditions on the LIBERO simulation benchmark:
Condition A (Full model): GR00T N1 as published - Eagle-2 VLM + DiT action policy, trained end-to-end.
Condition B (Ablated VLM): Replace Eagle-2 with a frozen, non-pretrained vision encoder of equivalent parameter count. The action policy architecture and training remain identical. The only variable removed is internet-scale VLM pretraining.
Condition C (Minimal vision): Replace Eagle-2 with a ResNet-50 encoder (25M parameters, no language capability). Action policy still receives visual tokens.
Measure task success on seen objects and unseen objects.
My prediction: Condition B shows modest degradation on seen objects (less than 10%) and substantial degradation on unseen objects (30-50%). That would confirm the VLM’s value is primarily in zero-shot generalization, not in base task competence. Condition C shows whether the 1.34B-parameter backbone earns its compute cost over a 25M-parameter encoder.
If the generalization delta between A and B is smaller than 15%, the VLM backbone may be earning its compute cost primarily on the long tail of novel objects, not on the bread-and-butter tasks that dominate production deployments. That distinction matters for how teams allocate compute between reasoning and control, in both driving and robotics.
In production, every component has to justify its compute cost and the only way to know if it does is to ablate it and measure the delta. I’ve found that teams rarely run this experiment, which means they often can’t answer the most basic question: what does this module actually buy us?
To my knowledge, nobody has published this ablation cleanly. The team that does will settle a question the field has been debating by intuition: how much of the VLM backbone is load-bearing, and how much is convention?
Components will keep converging. System architecture will remain domain-specific because the constraints are physical, not aesthetic. A CTO building for 200 Hz humanoid control and a CTO building for regulatory-certifiable L4 driving are optimizing against different objective functions, even when their model architectures share the same building blocks.
Reading the Map
If you’re a technical leader choosing an architecture, the decision tree maps your constraints to a starting strategy.
Two meta-observations worth calling out.
For investors: ask which quadrant the company occupies and whether their data strategy matches. A team pitching monolithic E2E without fleet-scale data has a structural mismatch. A team pitching single-system VLA for a 35-DoF humanoid without a plan for the tokenization wall has another.
For engineering leaders: org structure predicts architecture. If you organize around “perception” and “planning” as separate groups, you’ll build Strategy 1 whether you intend to or not. Organize around “foundation model training” and “real-time inference,” and you’ll gravitate toward Strategy 4.
This map has four strategies and two domains. In eighteen months, we’ll know whether one strategy subsumes the others or whether the physical constraints keep all four alive. Either way, the teams that read the map correctly will have a meaningful head start.
Stay on the signal path. - Vinay
If you found this useful, the previous article maps the $160B investment landscape that produced these four strategies: The AV Scoreboard: What $160 Billion Reveals About Generalists, Specialists, and Who Will Win in Physical AI